HAI
Published independent research: “The Brain Instruction Set — a model-invariant basis of semantic primitives in LLMs, from behaviour to mechanism.”
HAI (Human Artificial Intelligence) investigates the Brain Instruction Set (BIS) hypothesis — that human cognition can be represented in a vector space with a shared, semantically grounded core plus an individual binding layer. The idea dates back to 2000 and is now testable against real language models.
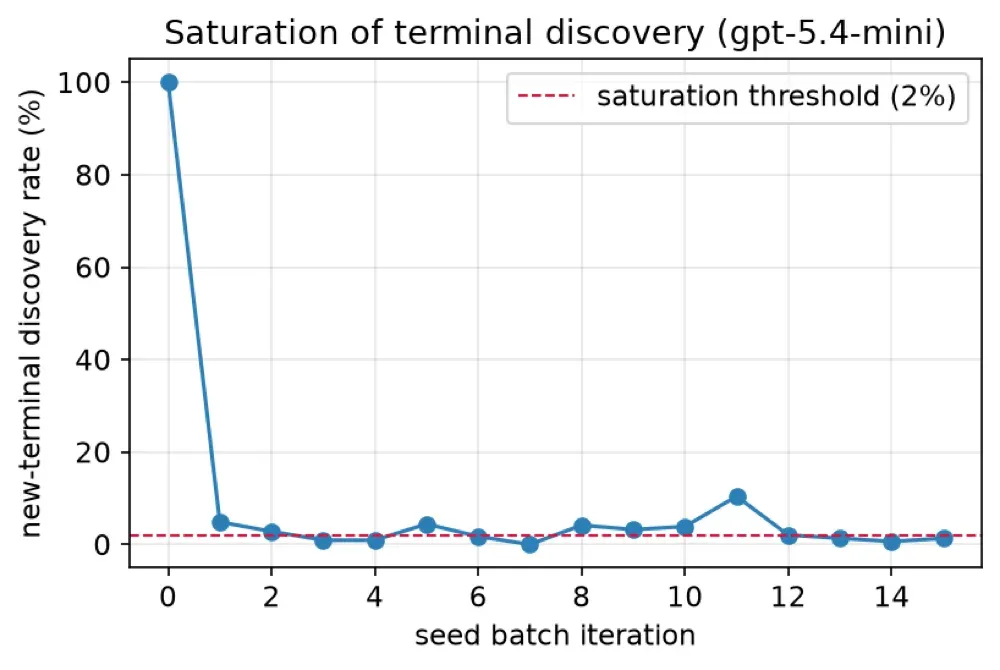
By recursively decomposing a graph of 13,534 concepts and 44,682 weighted edges, the study recovered a finite, shared basis of 152 verified semantic “terminals” across 9 modalities — with the discovery of new terminals saturating below 2%, supporting the finiteness claim. A cross-model core of 16 terminals was independently confirmed by both an OpenAI and an Anthropic model (81% modality concordance).
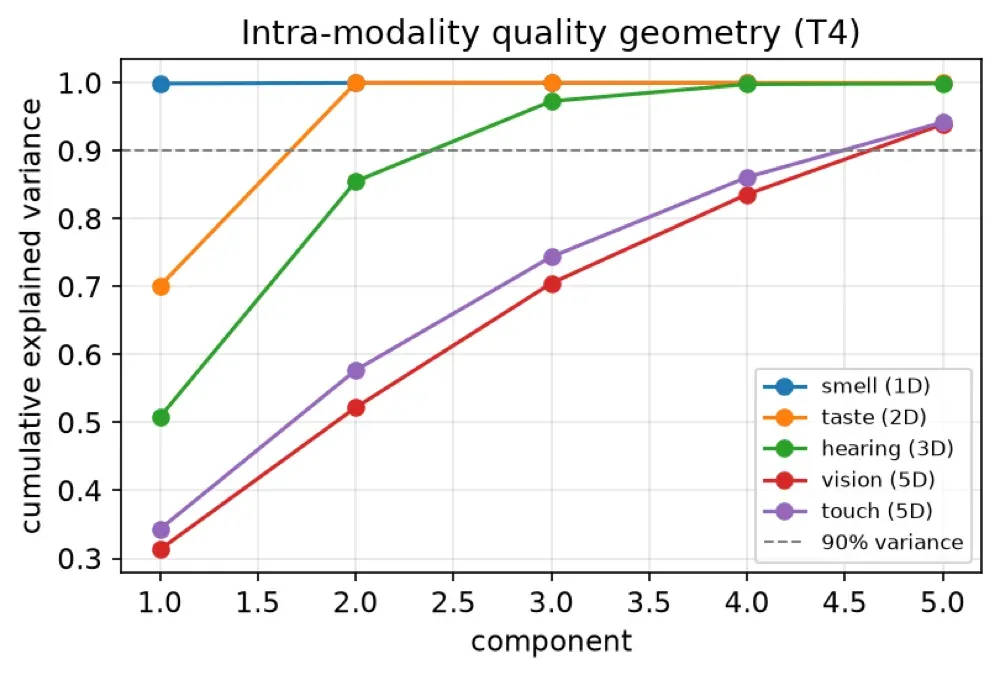
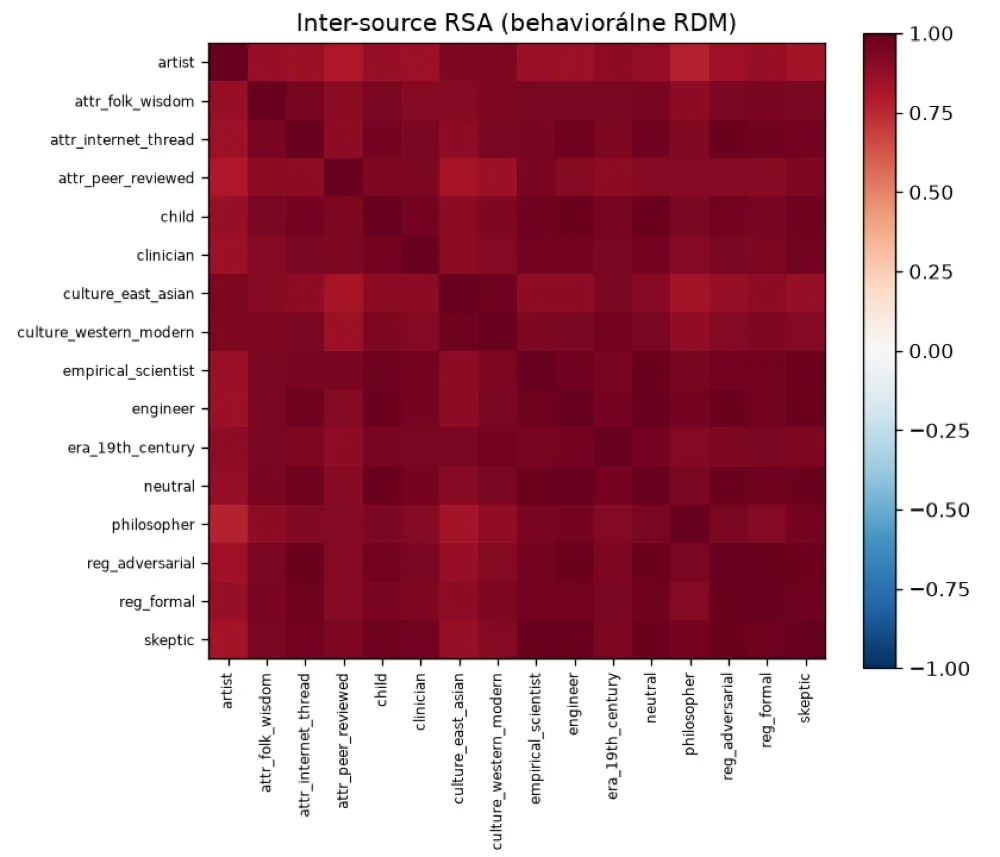
Two validity gates replicated across three models from two labs: inter-source representational similarity was high (RSA = 0.929), source perspective was decodable from content alone at 98.4%, and the terminal-similarity geometry reproduced known psychophysics without sensory supervision (smell ≈ 1D, taste ≈ 2D, hearing ≈ 3D, vision/touch ≈ 5D). The study explicitly measures the structure of representations, not phenomenal qualia.
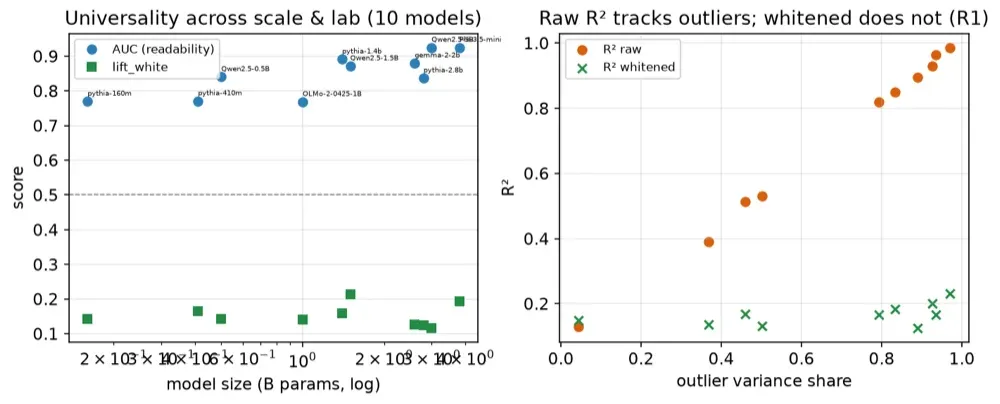
Beyond behaviour (v1.2), BIS moves toward a mechanistic basis: probing open-weight models (Gemma-2-2B, Qwen2.5-1.5B, Phi-3.5-mini) shows the terminals are linearly readable (AUC 0.86–0.93) and causally steerable, variance explained peaks mid-network (R² = 0.59 at layer 14), and the core aligns with independent sparse-autoencoder features (Gemma Scope).
Highlights
- 152 verified semantic “terminals” across 9 modalities
- Decomposed a graph of 13,534 concepts / 44,682 edges; discovery saturates below 2%
- Cross-model core of 16 terminals confirmed by both OpenAI and Anthropic models
- Inter-source similarity RSA = 0.929; perspective decodable at 98.4%
- Reproduces psychophysics (smell 1D, taste 2D, hearing 3D, vision/touch 5D) with no senses
- Mechanistic: terminals linearly readable (AUC 0.86–0.93) & causally steerable across 3 architectures; aligns with SAE features